
In vielen Produktionsunternehmen laufen die Maschinen rund um die Uhr. Die Organisation erfolgt dabei über spezialisierte IT-Systeme, wie beispielsweise ein Manufacturing Execution System (MES). Ein MES ist Teil eines Fertigungsmanagementsystems und damit für die Produktionssteuerung verantwortlich.
An ein solches System werden hohe Ansprüche in Sachen Verfügbarkeit gestellt. Denn: Fällt das System aus, steht auch die Produktion. Bei größeren Firmen können die Kosten durch solche Stillstände schnell in die Millionen gehen.
Die IT-Systeme müssen deshalb stets verfügbar sein. Sie müssen nicht nur gegenüber technischen Ausfällen geschützt sein, sondern auch physische Schäden, z.B. durch Brände oder Wasserschäden, überstehen können.
Aber wie sorgt man dafür, dass das System jederzeit einsatzbereit ist?
In der Praxis werden deshalb redundante Server eingesetzt. Dabei handelt es sich um mehrere Server (ein Cluster), wobei auf jedem das MES ausgeführt werden kann. Einer dieser Server arbeitet produktiv, die anderen befinden sich im Standby. Fällt das Produktivsystem aus, wird auf einen anderen Server gewechselt und das MES läuft dort weiter.
Viele Systeme setzen dabei zwar auf räumlich getrennte Server, aber auf eine zentrale Datenspeicherung.
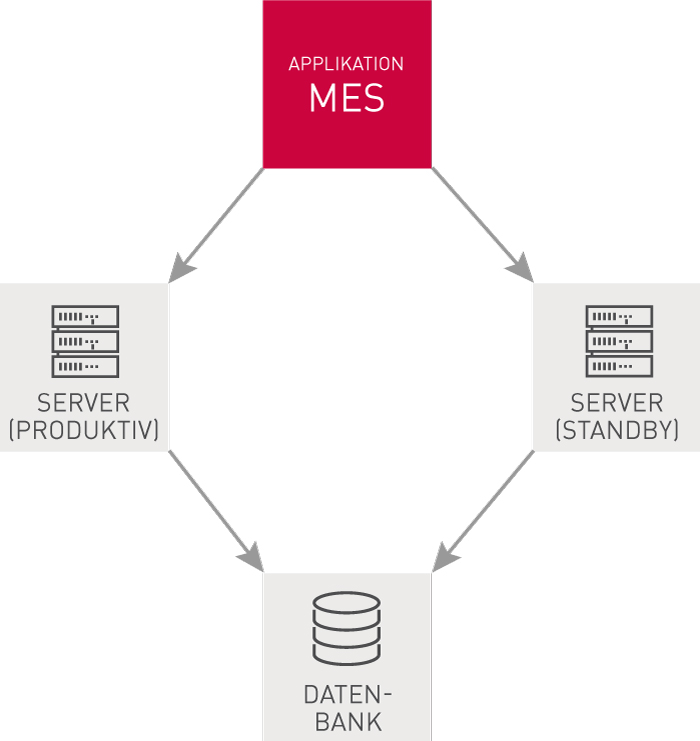
Das Problem: Diese zentrale Datenbank stellt eine Schwachstelle dar – ist sie beschädigt, fällt das gesamte System aus und das trotz redundanter Server.
Die Lösung sind getrennte Server mit jeweils einer eigenen Datenbank. Hierbei gilt es jedoch zwei Herausforderungen zu meistern:
- die Synchronisation der Daten auf den Datenbanken und
- das korrekte Umschalten bei Fehlern auf einen anderen Server.
Ausfallsicherheit bei ccc
Für unser eigenes MES haben wir als Hochverfügbarkeitslösung einen Ansatz gewählt, der das Konzept der Oracle Standby Datenbanken nutzt und den HP Serviceguard als Cluster Management System einsetzt. Im Folgenden wollen wir kurz erklären, wie dieser Ansatz funktioniert und wie wir mit den genannten Herausforderungen umgehen.
Der HP Serviceguard ist eine Cluster Management Software von Hewlett-Packard, die die Hochverfügbarkeit von IT-Systemen in Form eines Aktiv / Passiv-Clusters zur Verfügung stellt. Dabei übernimmt ein Rechner im Cluster aktiv die zugewiesenen Aufgaben (Primärsystem), während die übrigen Systeme passiv im Hintergrund laufen (Standby) und nur bei Ausfall des Primärsystems aktiv werden.
Übrigens: Wenn Sie gerade auf der Suche nach einem MES sind, dann wird Ihnen auch unser Guide „MES-Auswahl in 5 Schritten“ gefallen.

Korrekte Synchronisation
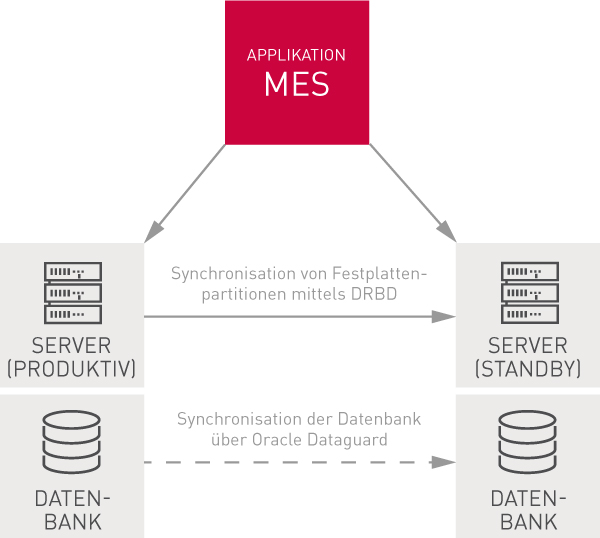
Um sicherzustellen, dass die Daten auf jedem Server in der gleichen Form vorliegen, nutzen wir die Oracle Enterprise Datenbank mit dem Konzept der Oracle Standby Datenbank und dem Oracle Dataguard. Letzterer stellt dabei sicher, dass vorgenommene Änderungen an den Daten auf die anderen Datenbanken übertragen werden.
Der Vorteil: Wenn ein Nutzer Daten in die Datenbank eingibt, bekommt er erst dann eine Rückmeldung, wenn die Änderungen auch an die anderen Datenbanken übertragen wurden. Dafür sorgt der Dataguard. So gehen keine Daten verloren.
Bei Ausfall einer Datenbank bekommt der Nutzer bei Eingabe trotzdem eine positive Rückmeldung. Die Daten werden in diesem Fall später synchronisiert – sobald die entsprechende Datenbank wieder verfügbar ist.
Die Synchronisation von Partitionen auf Betriebssystemebene kann über DRBD (Distributed Replicated Block Device) erfolgen. Die Funktionsweise ähnelt dabei dem eines Raid Controllers, nur auf Netzwerkebene.
RAID ist ein Akronym für englisch „Redundant Array of Independent Disks“, also „Redundante Anordnung unabhängiger Festplatten“. Ein RAID-System dient zur Organisation mehrerer physischer Massenspeicher zu einem logischen Laufwerk, das eine höhere Ausfallsicherheit oder einen größeren Datendurchsatz erlaubt als ein einzelnes physisches Speichermedium.
Bei Fehlern auf andere Server umschalten
Es sind drei Schritte notwendig, um sicherzustellen, dass der Serviceguard bei einem Fehler automatisch auf einen anderen Server umschaltet.
1. Pakete festlegen
Das Clusterkonzept setzt auf sogenannten Paketen auf. Ein Paket enthält alles, was für das funktionierende System wichtig ist – eine virtuelle IP-Adresse, die zugehörigen Anwendungen sowie Start-, Stop- und Monitor-Skripte.
Der Serviceguard stellt dabei sicher, dass ein Paket jeweils nur auf einem Server aktiv ist.
2. Regeln definieren
Was passiert, wenn ein Server ausfällt? Mit Regeln kann das gewünschte Verhalten des Systems bei einem Ausfall festgelegt werden. So wird zum Beispiel definiert, dass bei einem Fehler das System auf einem Server komplett stoppt und auf einem anderen hochgefahren wird.
3. Überwachungsmechanismen festlegen
Hierbei wird definiert, welche Unregelmäßigkeiten wie zu erkennen sind. Die Server überwachen sich dabei gegenseitig – auf jedem einzelnen läuft der Serviceguard und überwacht die anderen. In der Regel handelt es sich hierbei vor allem um Tests der Erreichbarkeit von IP-Adressen.
Split Brain vermeiden
Bei Start und im Fehlerfall übernimmt ein Quorum-Server (ein vom Rest des Clusters unabhängiges System) die Initialisierung des Clusters und verhindert damit das sogenannte Split Brain Phänomen.
Split Brain ist ein unerwünschter Zustand eines Clusters, bei dem alle Zwischenverbindungen zwischen den Clusterteilen gleichzeitig unterbrochen sind. Obwohl dabei mindestens zwei Teile noch funktionieren, ist zwischen ihnen keine Koordination mehr möglich.
Das führt bei Schreibzugriffen zu massiven Konflikten: Die Schreibvorgänge verteilen sich über die (zwar funktionierenden aber voneinander isolierten) Teile des Clusters. Die Datenstände laufen dabei auseinander und die Konsistenz der Daten ist nicht mehr gewährleistet.
Fazit
Wenn in einem Unternehmen ein fertigungssteuerndes IT-System, wie z.B. ein MES, zum Einsatz kommt, dann muss dieses System ständig verfügbar sein. Fällt es aus, steht die ganze Produktion.
Solche Systeme müssen deshalb technisch so aufgebaut sein, dass sie vor Ausfällen geschützt sind. Das kann zum Beispiel über redundante Server mit jeweils einer eigenen Datenbank erfolgen.
Wir bei ccc nutzen dafür das Konzept der Oracle Standby Datenbanken und den HP Serviceguard als Cluster Management System. Der Vorteil: Dieser Ansatz verzichtet im Gegensatz zu vielen anderen Systemen auf eine zentrale Datenbank, da diese einen Schwachpunkt darstellt.
Schreibe einen Kommentar